
Legal Drafting System: Multi-Agent RAG for Legal Petitions
October 27, 2025 · 4 min read
During my internship at Virtual Galaxy, I was given an interesting challenge: build a Proof of Concept that could take a legal petition and automatically draft a reply based on thousands of past judgments.
It sounds straightforward, but legal data is messy. I was working with over 2,000 PDF judgments, and accuracy was non-negotiable. A standard "search and summarize" tool wouldn't work because lawyers don't just need similar text—they need specific, binding precedents.
Here is how I built a Multi-Agent RAG system to solve it.
The Architecture: An AI Pipeline
I quickly realized that a single AI model couldn't handle the complexity of legal reasoning alone. It would hallucinate facts or miss the nuance between "murder" and "culpable homicide."
Instead, I engineered an AI Pipeline—a chain of specialized agents working together.
- The Planner: When you ask a question, the system doesn't just search blindly. An "Orchestrator" agent first analyzes your intent. It decides if you are asking for specific case law, a broad summary, or legal advice, and then creates a strict JSON plan to execute the search.
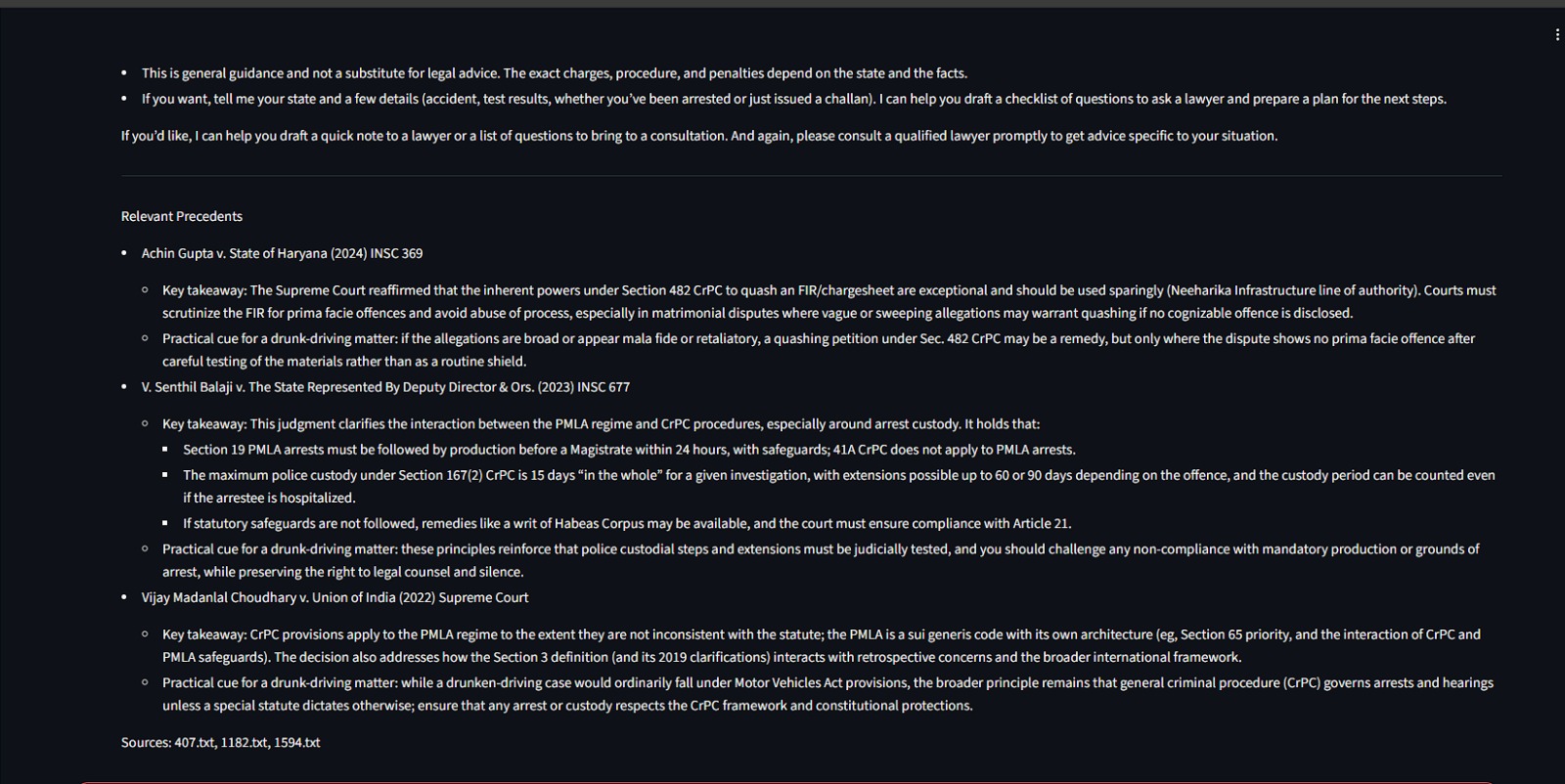
- Hybrid Retrieval: To find the needle in the haystack, I couldn't rely on just one type of search. I combined Vector Search (for concepts) with Keyword Search (for exact court names or dates) using a technique called Reciprocal Rank Fusion. This ensures the most relevant cases bubble to the top.
- Filtration: Before the AI answers, a "Filtration Agent" reads the retrieved documents. It acts like a senior lawyer, throwing out irrelevant cases and deciding if we need to load the full text of a judgment or just its summary.
Privacy & Local LLMs
Given the sensitive nature of legal data, the system was designed to run completely offline. Using Ollama, it can run local models (like Llama 3 or Mistral) on-premise, ensuring no client data ever leaves the secure environment.
Note on the Demo: While the production architecture supports fully local execution, the public demo hosted on my personal server uses external APIs (OpenAI) for performance reasons, as running high-context local models requires significant GPU compute.
How It Works
To test this architecture, I built two distinct modes into the application.
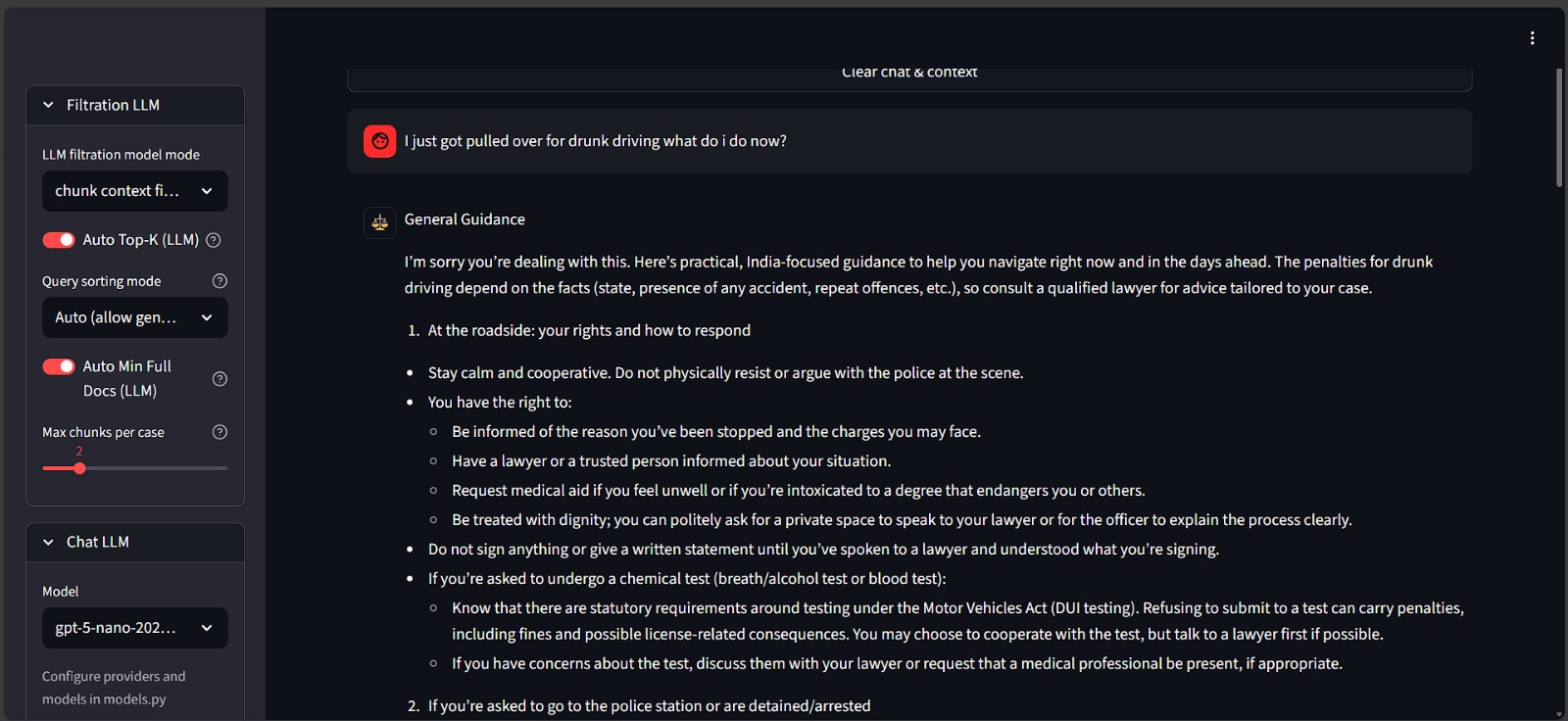
1. The Chat Interface
This isn't just a standard chatbot. I wanted to see if the system could handle different types of legal complexity, so I designed it to adapt to the user's question.
- Advisory Queries: You can ask something personal like, "I was arrested for bribing an officer, what should I do?" The system retrieves relevant legal provisions (like the PC Act) and gives procedural advice.
- Broad Summarization: You can also ask, "Summarize all bribery cases from 2025." The Planner recognizes this requires a broad search, pulls multiple documents from that year, and synthesizes them into a single report.
2. Petition Drafting
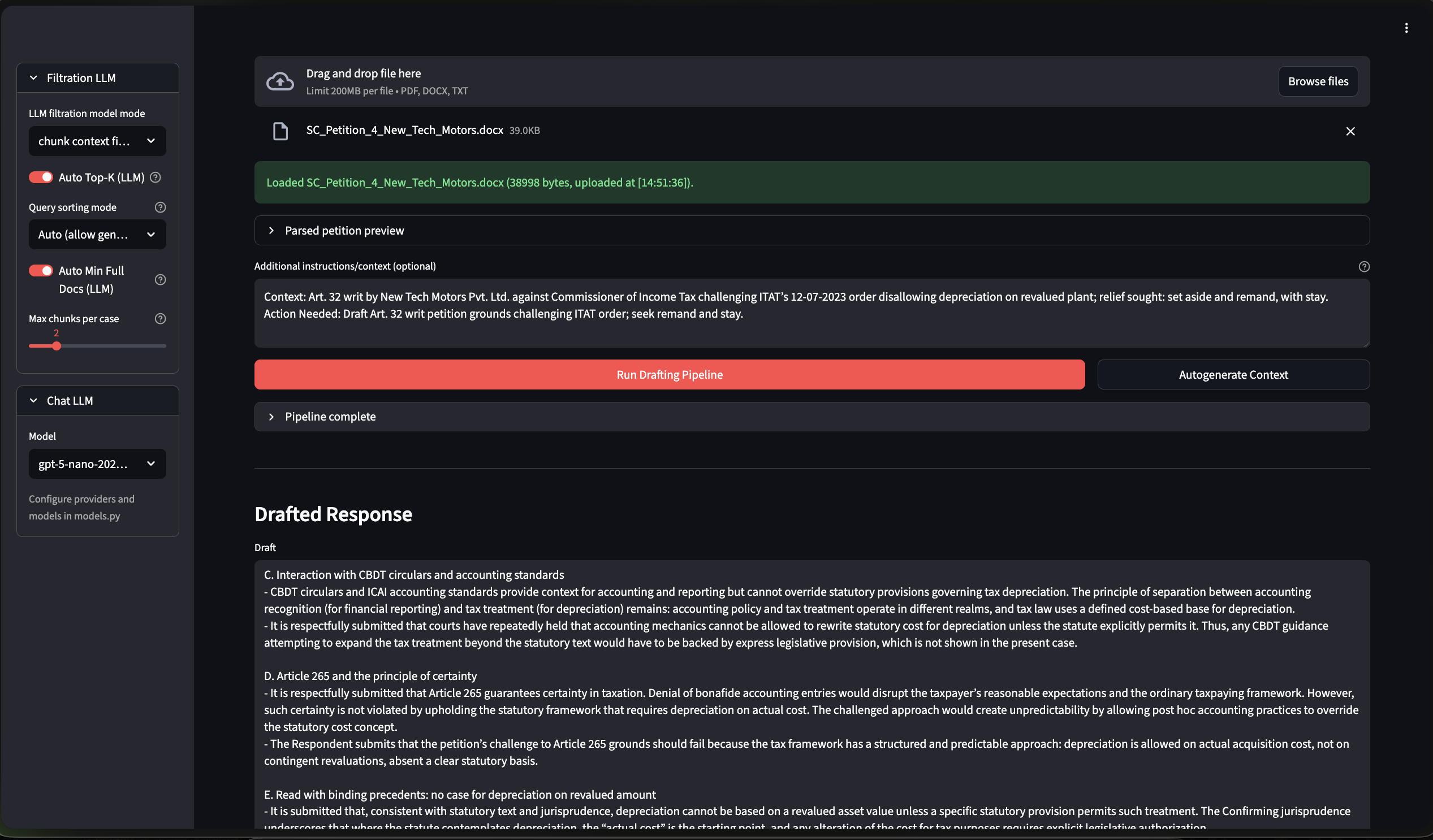
This was the core goal of the internship. The user uploads a PDF petition, and the system scans it to identify the "fighting points"—the specific allegations that need rebutting.
It then searches the database for precedents that favor the respondent and drafts a formal legal reply, complete with placeholders for facts it doesn't know. It's designed to never invent details, only using what is in the database or the uploaded file.
The Challenge: Precision at Scale
The hardest part of this project was getting the RAG (Retrieval-Augmented Generation) to be precise. With thousands of documents, standard search often returns noise.
I had to dive deep into advanced techniques like Re-Ranking and Metadata Enrichment. By extracting structured data (like Petitioner vs. Respondent) from the raw PDFs before they even hit the database, I was able to make the search significantly smarter.
Try It Out
I've hosted a demo of the project here: lds.vanshraja.me
What I Learned
This project was my deep dive into "Advanced RAG." I learned that building an AI wrapper is easy, but building a system that can reliably handle professional-grade data requires a lot of engineering under the hood. I'm proud of how the agents coordinate to solve problems that a single model couldn't handle on its own.